

Benefits of data extraction.
Enhanced decision-making:
Data extraction can provide up-to-date information to inform data-driven decisions, improving business strategy and outcomes.
Better data quality:
Automated data extraction minimizes errors in data migration and formatting, for accurate and reliable data.
Improved efficiency:
Automated data extraction works nonstop and at high speed, saving time and allowing employees to focus on strategic, high-value activities.
Creating new value:
Data extraction can uncover valuable insights from otherwise unusable files and datasets, transforming latent data into valuable resources like targeted leads and operating costs.
Fueling AI and machine learning:
By distilling all types of data into organized and centralized information repositories, data extraction can deliver high-value insights for training AI models.
Deeper business intelligence:
Supports business intelligence initiatives, helping businesses derive insights from data to fuel innovation and competitive advantage.
Cost savings:
Reduces or eliminates manual work involved in data management, saving significant resources and costs.
Data handling at scale:
Data extraction software can process high volumes of data from multiple sources as well as smoothly handle increasing amounts of data, including unexpected changes in volume.
Data extraction and ETL.
The Extract, Transform, Load (ETL) process is a three-phase strategy to gather information, enhance its usability, and integrate it into a data ecosystem.
Starting with data extraction, this first phase involves tapping into information sources to collect essential data. Similar to the way input quality impacts an end product, ensuring comprehensive and reliable data is extracted sets the stage for the success of the entire ETL workflow. In the Transform phase, raw extracted data is refined to suit business objectives. Data transformation adds value by adjusting data to align with its intended use, removing extraneous components in the process. The Load phase represents the delivery of data to its destination, typically a database, where it is ready for use in business processes, planning, and analysis.
Each part of the ETL process is indispensable, but data extraction represents the first foundational step, enabling effective data transformation and integration downstream.
Data sources:
Before initiating an Extract, Transform, Load (ETL) process, data sources need to be identified. ETL tools can extract raw data from diverse sources, including structured databases and CRM systems, as well as unstructured sources such as email and websites.
Data extraction:
This is the first step of the ETL process. ETL tools extract raw data from the identified sources and temporarily store it in a staging area. Depending on the data source and purpose, the process could use full extraction or incremental extraction. Similarly, the frequency of extraction, whether in real time or at set intervals, depends on the specific needs of the business process or objective.
Data transformation:
Once data has been extracted, the transformation phase begins to clean, organize, and consolidate the raw information. Data may undergo a variety of transformations, including data cleansing, removal of duplicate data, and reformatting.
Data loading:
The final step in the ETL process is loading the transformed data. This data, now refined and error-free, is transferred and stored in the target data warehouse. Depending on the data volume and business requirements, loading could be all at one time or incrementally. Once loaded, data is ready for retrieval and analysis.
Data extraction methods and tools.
Automation can only go as far as the data available, making effective data extraction and organization the lynchpin to automating most business processes. Different data extraction methods and tools are used to gather information from data sources in different formats. In particular, AI-powered Intelligent Automation technologies are necessary to glean data from unstructured sources such as emails and business documents.
Structured data extraction
Structured data, characterized by its preorganized format and easy accessibility, typically resides in databases, spreadsheets, and customer relationship management (CRM) systems. Extracting structured data tends to be straightforward and uses a range of techniques such as SQL queries, API calls, and specific database management tools.
However, structured data still comes with data extraction challenges. High data volume can slow extraction processes, while data siloed in disconnected systems may present integration complexities. And extracting sensitive data, such as customer information, presents privacy, compliance, and security considerations.
Common methods of structured data extraction:
- Structured query language (SQL) is the standard language for interacting with relational databases. SQL queries are powerful tools for extracting, manipulating, and managing data.
- Application Programming Interfaces (APIs) allow systems to communicate and exchange data programmatically. They are essential for extracting data from cloud-based applications and services.
- Database management tools are specialized for managing and extracting data from structured sources, typically offering user-friendly interfaces with additional, more advanced capabilities available. Specialized data extraction tools include:
- ETL tools to automate the process of data extraction, transformation, and loading into data warehouses.
- Data integration platforms that facilitate integrating data from multiple structured sources into a single system.
- CRM data extractors pull data from CRM systems for analysis and reporting.
Semi-structured data extraction
Unlike structured data, semi-structured data does not adhere to a fixed schema but does contain tags and markers that provide an organizational hierarchy. Common sources of semi-structured data include XML files, JSON files, and web data.
Extracting semi-structured data presents a unique set of challenges due to the variability and variety of the data, which makes standardization and normalization more complex to accomplish. Similar to unstructured data, the sheer volume and pace at which semi-structured data is generated can make ongoing data extraction more challenging. Additionally, some data formats, like XML and JSON files, can have nested structures that require the application of specific parsing techniques.
Common methods of semi-structured data extraction:
- eXtensible Markup Language (XML) files are widely used for data representation and exchange. XML parsers are essential for reading and extracting data from XML documents.
- JavaScript Object Notation (JSON) is a lightweight data interchange format popular for its simplicity and readability. JSON data extractors parse and process JSON files.
- Web scraping involves extracting data from websites, which tend to present information in semi-structured formats. Web scraping tools automate the process of retrieving web data.
Unstructured data extraction
Unstructured data is the wild child of business information: Unpredictable yet with immense potential to create value. And the reality is that the majority of data exists in unstructured format, scattered across emails, documents, and chats, as well as audio, video, and image files. Harnessing unstructured data sources to extract insights requires advanced methods and technologies such as NLP, OCR, and AI-powered text analytics tools to overcome the challenges inherent to processing complex data that has no predefined schema.
Challenges particular to unstructured data extraction include the volume and diversity of data together with its context—sarcasm in chat conversations or out-of-context use of terminology—that creates unprecedented complexity. Ensuring accuracy and data integrity are also challenges due to the noise and variation inherent in unstructured data sources.
Common methods of unstructured data extraction:
- Optical character recognition (OCR) technology converts different types of documents, such as scanned paper documents, PDFs, or digital images, into editable and searchable data.
- Natural language processing (NLP) is a core technology for extracting and understanding unstructured text. NLP includes several techniques:
- Tokenization: Breaking down text into individual words or phrases
- Named entity recognition (NER): Identifying and classifying entities such as names, dates, and locations.
- Sentiment analysis: Analyzing the sentiment behind the text to gauge public opinion or customer feedback.
- Text summarization: Extracting key points from large documents.
- Other AI-powered text analytics tools combine machine learning and deep learning techniques to extract insights from unstructured data. Techniques include topic modeling to identify main topics in a large body of text, clustering to group similar documents or text snippets, and predictive analytics to make future trend predictions using historical data.
Use cases for data extraction automation.
Banking and Financial Services
- Loan processing: Applying automated data extraction to loan applications enables assessing borrowers' financial health and repayment capacity in real time.
- Customer onboarding: Extracting data automatically from account opening forms accelerates account setup.
- Financial reporting: Data extraction automation supports accurate and timely expense tracking, budgeting,
- Know Your Customer (KYC): Automating the extraction of customer information from account opening forms helps accelerate verifying customers’ identities.
Healthcare
- Medical record management: Automating data extraction accelerates organizing and managing medical records, supporting the accuracy and accessibility of patient information.
- Administrative efficiency: Data extraction automation reduces administrative workload while increasing accuracy and speed, freeing staff to focus on patient care.
- Regulatory compliance: Data extraction automates the process of collecting required data from compliance-related documents.
- Electronic health records (EHR): Automated data extraction enables the adoption of electronic health records, facilitating efficient storage, retrieval, and sharing of patient data.
Insurance
- Policy document management: Automating data extraction from policy documents helps ensure accurate insurance coverage terms and conditions.
- Claims processing: Automated data extraction from claim forms enables capturing incident details as quickly as possible.
- Customer service: Using data extraction automation on communication records helps track customer service interactions to enhance the overall customer experience.
- Identity verification: Automating data extraction from proof of identity documents helps prevent fraud.
Accounting and Finance
- Invoice processing: Data extraction plays a key role in automating invoice processing by accurately pulling relevant details from invoices.
- Tax compliance: Extracting data from tax forms supports the correct calculation of tax obligations and disclosures.
- Financial reporting: Automating the extraction of data from financial statements helps establish an accurate picture of an organization's financial health, supporting better decision-making and transparency.
- Purchase order processing: Automated data extraction from purchase orders enables the creation of reliable records of purchase, speeding payment processing and supporting budget management.
Evolution of data extraction technology.
Better, faster data extraction
Collecting, inputting, and managing business data represented a significant manual effort for organizations—think of the work of data entry alone—inspiring many of the first data extraction automation tools, such as OCR, to streamline and accelerate data extraction processes. Extracting the right information and structuring the data into a usable format was improved by the introduction and refinement of tools like SQL and Extract, Transform, Load (ETL) processes that enabled the automation of data extraction. However, data extraction remained largely rule-based and dependent on structured data.
Breaking the structure barrier with ML
Along with the introduction of robotic process automation (RPA), the integration of AI and machine learning (ML) represented a major breakthrough in data extraction technology. More accurate data extraction from more diverse and complex sources was made possible by ML algorithms that learn from historical data to improve accuracy and efficiency over time. ML models, trained to recognize and extract specific data points from semi-structured sources like emails or invoices, powered a major reduction in the need for manual intervention in data extraction, enabled data mining, and dramatically increased the speed of data processing.
Understanding natural language
The application of natural language processing (NLP) technology further transformed the scope and capabilities of data extraction tools. The ability to interpret human language with NLP technologies meant data extraction processes could encompass unstructured text data, including customer inquiries and business documents, to glean valuable information. NLP algorithms go even further, enabling the understanding of context, sentiment, and intent of unstructured text data at scale.
Infinite potential with AI + automation
Combining AI, machine learning, NLP, and generative AI with cognitive automation systems opens up the possibility of performing complex data extraction tasks with minimal human intervention. Intelligent document processing (IDP) and advanced AI-driven automation systems are capable of understanding context, learning from new data, and adapting to change, making nearly any data extraction task fair game for automation, including unstructured data sources such as audio, video, and images. AI-powered data extraction enables organizations to collect and capitalize on the insights and value within ever-growing data repositories to derive deeper insights and fuel innovation in the data-driven economy.
Getting started with data extraction automation.
Identify data sources
Since the data you extract is dependent on its source, identifying your data source is an obvious starting point for setting up any data extraction process. Source data for extraction may include databases, websites, logs, or even physical documents.
Design the data extraction workflow
Examine each stage of the extraction process to map out the workflow and define rules for data handling and processing. Start by setting up the connection to your data sources, then extract the data, transform it, validate it, and finally load the data into its destination.
Develop and test
Depending on the source of your data, you'll need to employ different data extraction tools and techniques, such as web scraping, database querying, API calls, OCR, file parsing, and NLP. Plan for comprehensive testing in a sandbox or other controlled environment and fully document the end-to-end extraction process to support any potential troubleshooting.
Deploy and schedule
Schedule the extraction to run at specific intervals or based on certain triggers or conditions to ensure maximum productivity and minimal disruption.
Monitor and maintain
Monitor the extraction process for ongoing data quality and accuracy. Regular review and maintenance can help avoid unexpected failures or performance issues due to fluctuations in data volume or changes in the source format. Last but not least, be sure to establish data security protocols and compliance reviews.
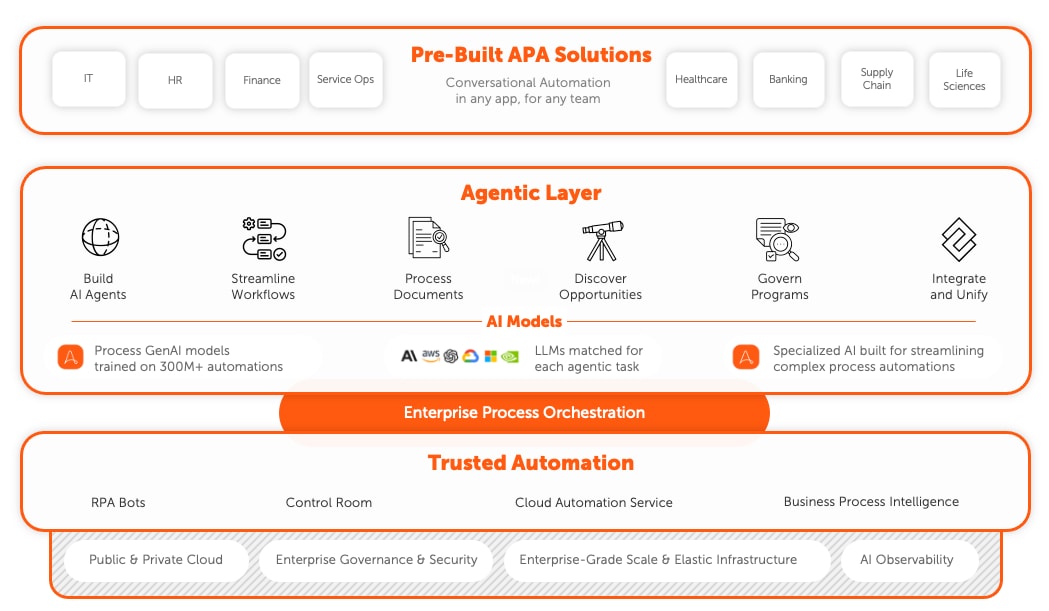
Extract full value from your data with a complete Intelligent Automation solution.
Get the most advanced data extraction capabilities with Document Automation, built into Automation Anywhere’s AI + Automation Enterprise System. Seamlessly identify, collect, and inject data into any process or workflow.
Frequently Asked Questions.
How does data extraction differ from data integration?
Data extraction involves retrieving data from different sources, such as databases, semi-structured sources like XML or JSON files, and unstructured sources like text documents or web pages. The primary goal of data extraction is data collection—gathering relevant data for further use, such as analysis, reporting, or feeding into other applications.
Data integration, on the other hand, refers to the process of combining data from different sources and providing a unified view of this data. This involves not only extracting data but also transforming and loading it into a centralized system, such as a data warehouse. Integration processes ensure that data from disparate sources is harmonized, consistent, and accessible for various business applications and analytics.
What are the common formats for extracted data?
When data is extracted, it can be presented in different formats depending on the data source and how the data will be used. Each format has its own advantages and is usually chosen based on the requirements of the data processing task at hand. Some common formats for extracted data include:
Comma-Separated Values (CSV) format is widely used for its simplicity and compatibility with many applications. In CSV format, each line represents a record, and fields are separated by commas.
JavaScript Object Notation (JSON) is a lightweight data interchange format that is both easy for people to read and write and easy for systems to parse and generate. It is most commonly used in web applications and APIs.
eXtensible Markup Language (XML) is a flexible text format often used for data exchange between systems that allows for the definition, transmission, validation, and interpretation of data.
Excel (XLS/XLSX) is a spreadsheet format used by Microsoft Excel. It is suitable for tabular data and is widely used in business environments. The Excel format supports complex data structures and formulas.
Plain Text format is simple text files that can contain unstructured or semi-structured data. Plain text is often used for logs, reports, and documentation.
Structured Query Language (SQL) format is used for managing and manipulating relational databases. Data can be extracted in SQL format for direct import into other database systems.
HyperText Markup Language (HTML) is the standard markup language for documents designed to be displayed in a web browser. Data extracted from web pages often comes in HTML format.
Portable Document Format (PDF) is a file format developed by Adobe that presents documents in a manner independent of application software, hardware, and operating systems. PDF format is often used for official documents, forms, and reports.
What are the challenges of real-time data extraction?
Real-time data extraction involves capturing and processing data as it is generated or received, which presents unique challenges to infrastructure, integrations, and error handling.
Real-time data extraction systems must be ready to handle large volumes of data arriving at high speeds. This requires robust infrastructure to ensure data can be processed without delays and minimal latency while ensuring the accuracy and consistency of incoming data.
Integrating real-time data extraction with systems or workflows that were not designed for real-time data handling presents another challenge. In addition, real-time processing requires significant computational resources, which can be costly and challenging to manage, particularly during peak data flow periods.
Keeping real-time extraction compliant with data security and privacy regulations, including ensuring secure data transmission and storage, is critical, especially for sensitive information. Security and privacy issues can be compounded by the complexity of analyzing and responding to data being generated in real time. Handling unexpected scenarios requires sophisticated algorithms and processing capabilities to detect patterns and anomalies.
What are the cost implications of data extraction?
The cost implications of data extraction span a wide range of factors, including infrastructure, data storage, security, and scale.
Setting up and maintaining hardware and software infrastructure for data extraction is a non-trivial investment. This includes servers, storage, networking equipment, and cloud services. Purchasing or subscribing to data extraction tools and platforms is part of this cost equation.
Customizing and developing data extraction solutions and any required integrations to fit specific business needs is an expense in terms of development time and expertise.
Data storage, whether on-premises or in the cloud, and ongoing operational costs, including maintenance, monitoring, and support, come with associated costs. As data volumes grow, storage and operating costs may increase, as may infrastructure needs.
How can I handle authentication and authorization challenges during data extraction?
Handling authentication and authorization challenges during data extraction requires implementing security measures to restrict data access and extraction to authorized users and systems only. It is also important to comply with relevant standards and regulations for authentication and authorization (e.g., GDPR, HIPAA, PCI DSS). No matter which security methods you use, conduct regular security assessments and penetration testing to identify and address vulnerabilities in authentication and authorization processes.
Strategies for secure authentication and authorization include:
- Using secure authentication protocols such as OAuth, SAML, or OpenID Connect to verify the identity of users and systems accessing the data.
- Enforcing multi-factor authentication (MFA) to add an additional layer of security, ensuring that access is granted only after multiple forms of verification.
- Configuring role-based access control (RBAC) and fine-grained access control to assign permissions based on users' roles at a granular level. This ensures that users have access only to the data necessary for their role.
- Employ token-based authentication to manage sessions securely. Tokens can be issued with specific scopes and expiration times to limit access.
- Encrypt data in transit and at rest to protect it from unauthorized access. Use SSL/TLS for data transmission and strong encryption standards for storage.
- Audit and monitor to track access and activities related to data extraction. This helps detect and respond to unauthorized access attempts.
- Ensure API security for APIs used for data extraction with rate limiting, IP whitelisting, and API gateways to prevent abuse and unauthorized access.
What are best practices for error handling and data validation in data extraction processes?
Effective error handling and data validation are pivotal to the reliability and accuracy of data extraction processes. Along with employing best practices for handling errors and validating data, nothing can replace effective documentation and training, as well as continuous process monitoring to ensure the reliability and accuracy of data extraction. Documenting error handling and data validation procedures thoroughly and providing training to make sure teams understand and follow best practices is always part of the foundation of successful data extraction processes. Continuously monitoring data extraction processes with dashboards and alerts helps keep track of key metrics and issues and enables detecting and responding to errors quickly.
Error handling and validation best practices include:
- Implement robust validation rules
Define and implement validation rules to check the accuracy, completeness, and consistency of extracted data. This can include format checks, range checks, and cross-field validations. - Use AI and machine learning
Leverage AI and machine learning techniques to enhance data validation by identifying patterns and anomalies that traditional rules might miss. - Include human-in-the-loop validation
Incorporate human validation for critical data points or when automated validation flags potential issues. This helps ensure high data quality. - Implement error logging and reporting
Set up comprehensive error logging and reporting mechanisms to capture details about errors, including their source, type, and context. This helps diagnose and resolve issues quickly. - Set up retry mechanisms:
Implement retry mechanisms for transient errors, such as network timeouts or temporary service outages. This ensures that temporary issues do not cause permanent data loss. - Define fallback procedures:
Establish fallback procedures for handling errors that cannot be resolved automatically. This can include manual intervention or alternative data sources. - Perform data cleansing
Use data cleansing to correct or remove inaccurate, incomplete, or duplicate data. This can be done as part of the extraction process or in a separate data processing step. - Apply version control
Maintain version control for data extraction scripts and configurations to track changes and ensure consistency across different environments. - Automate testing
Implement automated testing for data extraction processes to detect and fix issues before they impact production. This includes unit, integration, and performance tests.



