Benefícios da extração de dados.
Melhor tomada de decisões:
a extração de dados pode fornecer informações atualizadas para fundamentar decisões baseadas em dados, melhorando a estratégia e os resultados dos negócios.
Melhor qualidade de dados:
a extração automatizada de dados minimiza erros na migração e formatação de dados, para obtenção de dados precisos e confiáveis.
Melhor eficiência:
a extração automatizada de dados funciona de forma contínua e rápida, economizando tempo e permitindo que os funcionários se concentrem em atividades estratégicas e de alto valor.
Criação de novo valor:
A extração de dados pode revelar insights valiosos de arquivos e conjuntos de dados que, de outra forma, não poderiam ser utilizados, transformando dados latentes em recursos valiosos, como leads direcionados e custos operacionais.
Impulso da IA e do aprendizado de máquina:
ao distribuir todos os tipos de dados em repositórios de informações organizados e centralizados, a extração de dados pode fornecer insights de alto valor para o treinamento de modelos de IA.
Inteligência empresarial mais aprofundada:
oferece suporte a iniciativas de inteligência empresarial, ajudando empresas a obter insights de dados para impulsionar a inovação e a vantagem competitiva.
Economia de custos:
reduz ou elimina o trabalho manual envolvido no gerenciamento de dados, economizando recursos e custos de forma significativa.
Processamento de dados em escala:
o software de extração de dados pode processar grandes volumes de dados de diversas fontes, além de lidar facilmente com quantidades cada vez maiores de dados, incluindo alterações inesperadas no volume.
ETL e extração de dados.
O processo ETL (Extract, Transform, Load; extrair, transformar, carregar) é uma estratégia de três fases para coletar informações, melhorar a usabilidade delas e integrá-las a um ecossistema de dados.
Começando com a extração de dados, esta primeira fase envolve explorar fontes de informação para coletar dados essenciais. Assim como a qualidade da entrada afeta o produto final, garantir que dados abrangentes e confiáveis sejam extraídos prepara o cenário para o sucesso de todo o fluxo de trabalho de ETL. Na fase de transformação, os dados brutos extraídos são refinados para atender aos objetivos de negócio. A transformação de dados agrega valor ao ajustar os dados para alinhá-los ao uso pretendido, removendo componentes estranhos do processo. A fase de carregamento representa a entrega de dados ao seu destino, normalmente, um banco de dados, onde os dados estão prontos para uso em processos de negócios, planejamento e análise.
Cada parte do processo ETL é indispensável, mas a extração de dados representa o primeiro passo fundamental, permitindo a transformação e integração eficazes de dados posteriormente.
Fontes de dados:
antes de iniciar um processo de ETL, as fontes de dados precisam ser identificadas. As ferramentas ETL podem extrair dados brutos de diversas fontes, incluindo bancos de dados estruturados e sistemas de CRM, bem como fontes não estruturadas, como e-mail e sites.
Extração de dados:
este é o primeiro passo do processo ETL. As ferramentas ETL extraem dados brutos de fontes identificadas e os armazenam temporariamente em uma área de preparação. Dependendo da fonte de dados e da finalidade, o processo pode usar extração completa ou incremental. Da mesma forma, a frequência da extração, seja em tempo real ou em intervalos definidos, depende das necessidades específicas do processo ou objetivo do negócio.
Transformação de dados:
depois que os dados são extraídos, é iniciada a fase de transformação que limpa, organiza e consolida as informações brutas. Os dados podem passar por diversas transformações, incluindo limpeza de dados, remoção de dados duplicados e reformatação.
Carregamento de dados:
a etapa final no processo ETL é carregar os dados transformados. Agora, os dados refinados e livres de erros são transferidos e armazenados no data warehouse de destino. Dependendo do volume de dados e dos requisitos de negócio, o carregamento pode ser feito de uma só vez ou de forma incremental. Assim que são carregados, os dados estão prontos para recuperação e análise.
Métodos e ferramentas de extração de dados.
A automação abrange os dados disponíveis, o que torna a extração e a organização de dados com eficácia as peças fundamentais para automatizar a maioria dos processos de negócios. Diferentes métodos e ferramentas de extração de dados são usados para coletar informações de fontes em diferentes formatos. Em particular, tecnologias de Automação Inteligente impulsionadas por IA são necessárias para coletar dados de fontes não estruturadas, como e-mails e documentos comerciais.
Extração de dados estruturados
Dados estruturados, caracterizados por seu formato pré-organizado e de fácil acessibilidade, normalmente residem em bancos de dados, planilhas e sistemas de gerenciamento de relacionamento com o cliente (CRM). A extração de dados estruturados tende a ser simples e usa diversas técnicas, como consultas SQL, chamadas de API e ferramentas específicas de gerenciamento de banco de dados.
No entanto, os dados estruturados ainda apresentam desafios de extração de dados. Altos volumes de dados podem retardar os processos de extração, enquanto dados isolados em sistemas desconectados podem apresentar complexidades de integração. E ao extrair dados confidenciais, como informações de clientes, devem ser consideradas a privacidade, a conformidade e a segurança.
Métodos comuns de extração de dados estruturados:
- a linguagem de consulta estruturada (SQL) é a linguagem padrão para interagir com bancos de dados relacionais. As consultas SQL são ferramentas poderosas para extrair, processar e gerenciar dados.
- As APIs (Interfaces de programação de aplicativos) permitem que os sistemas se comuniquem e troquem dados de forma programática. Eles são essenciais para extrair dados de aplicativos e serviços baseados em nuvem.
- As ferramentas de gerenciamento de banco de dados são especializadas para gerenciar e extrair dados de fontes estruturadas, geralmente, oferecendo interfaces fáceis de usar com recursos adicionais mais avançados disponíveis. Ferramentas especializadas de extração de dados incluem:
- Ferramentas ETL para automatizar o processo de extração, transformação e carregamento de dados em data warehouses.
- Plataformas de integração de dados que facilitam a integração de dados de diversas fontes estruturadas em um único sistema.
- Os extratores de dados de CRM extraem dados de sistemas de CRM para análise e relatórios.
Extração de dados semiestruturados
Ao contrário dos dados estruturados, os dados semiestruturados não seguem um esquema fixo, mas contêm tags e marcadores que fornecem uma hierarquia organizacional. Fontes comuns de dados semiestruturados incluem arquivos XML e JSON, além de dados da web.
A extração de dados semiestruturados apresenta um conjunto único de desafios devido à variabilidade e variedade dos dados, o que torna a padronização e normalização mais complexas. Assim como os dados não estruturados, o grande volume e o ritmo em que os dados semiestruturados são gerados podem tornar a extração contínua de dados mais desafiadora. Além disso, alguns formatos de dados, como arquivos XML e JSON, podem ter estruturas aninhadas que exigem a aplicação de técnicas de análise específicas.
Métodos comuns de extração de dados semiestruturados:
- Arquivos XML (eXtensible Markup Language) são amplamente utilizados para representação e troca de dados. Analisadores XML são essenciais para ler e extrair dados de documentos XML.
- JSON (JavaScript Object Notation) é um formato leve de intercâmbio de dados, que é popular por sua simplicidade e legibilidade. Os extratores de dados JSON analisam e processam arquivos JSON.
- A raspagem de dados envolve a extração de dados de sites, que tendem a apresentar informações em formatos semiestruturados. Ferramentas de raspagem de dados automatizam o processo de recuperação de dados da web.
Extração de dados não estruturados
Dados não estruturados são os rebeldes das informações empresariais: imprevisíveis, mas com imenso potencial de gerar valor. E a realidade é que a maioria dos dados possui um formato não estruturado e fica espalhada por e-mails, documentos e bate-papos, bem como em arquivos de áudio, vídeo e imagem. Aproveitar fontes de dados não estruturados para extrair insights requer métodos e tecnologias avançadas, como PLN, OCR e ferramentas de análise de texto com tecnologia de IA para superar os desafios inerentes ao processamento de dados complexos que não têm um esquema predefinido.
Os desafios específicos da extração de dados não estruturados incluem o volume e a diversidade de dados, juntamente com seu contexto (sarcasmo em conversas de bate-papo ou uso de terminologia fora do contexto), o que cria uma complexidade sem precedentes. Garantir a precisão e a integridade dos dados também é um desafio devido ao ruído e à variação inerentes às fontes de dados não estruturados.
Métodos comuns de extração de dados não estruturados:
- A tecnologia de reconhecimento óptico de caracteres (OCR) converte em dados editáveis e pesquisáveis diferentes tipos de arquivos, como documentos impressos digitalizados, PDFs ou imagens digitais.
- O PLN (processamento de linguagem natural) é uma tecnologia essencial para extrair e compreender texto não estruturado. O PLN inclui várias técnicas:
- Tokenização: dividir o texto em palavras ou frases individuais
- Reconhecimento de entidade nomeada (NER): identificar e classificar entidades como nomes, datas e locais.
- Análise de sentimentos: analisar o sentimento por trás do texto para avaliar a opinião pública ou o feedback do cliente.
- Resumo de texto: extrair os pontos-chave de documentos grandes.
- Outras ferramentas de análise de texto com tecnologia de IA combinam técnicas de aprendizado de máquina e aprendizagem profunda para extrair insights de dados não estruturados. As técnicas incluem a modelagem de tópicos, para identificar os principais tópicos em um grande corpo de texto, agrupamento de documentos ou trechos de texto semelhantes, e a análise preditiva, para fazer previsões de tendências futuras usando dados históricos.
Casos de uso para automação de extração de dados.
Serviços bancários e financeiros
- Processamento de empréstimos: a aplicação da extração automatizada de dados em solicitações de empréstimo permite avaliar a saúde financeira e a capacidade de pagamento do mutuário em tempo real.
- Integração do cliente: a extração de dados de forma automática dos formulários de abertura de conta acelera a configuração da conta.
- Relatórios financeiros: a automação da extração de dados oferece suporte ao rastreamento preciso e oportuno de despesas e orçamento.
- KYC (Know Your Customer, Conheça seu cliente): a automação da extração de informações do cliente de formulários de abertura de conta ajuda a acelerar a verificação das identidades dos clientes.
Área da saúde
- Gestão de registros médicos: a automação da extração de dados acelera a organização e o gerenciamento de registros médicos, garantindo a precisão e a acessibilidade das informações do paciente.
- Eficiência administrativa: a automação da extração de dados reduz a carga de trabalho administrativa e aumenta a precisão e a velocidade, liberando a equipe para se concentrar no atendimento ao paciente.
- Conformidade regulatória: a extração de dados automatiza o processo de coleta de dados necessários dos documentos relacionados à conformidade.
- RES (Registro Eletrônico de Saúde): A extração automatizada de dados permite a adoção de registros eletrônicos de saúde, facilitando o armazenamento eficiente, a recuperação e o compartilhamento de dados do paciente.
Seguros
- Gerenciamento de documentos de apólices: automatizar a extração de dados de documentos de apólices ajuda a garantir termos e condições precisos da cobertura do seguro.
- Processamento de sinistros: a extração automatizada de dados de formulários de sinistro permite capturar detalhes do incidente o mais rápido possível.
- Atendimento ao cliente: o uso da automação de extração de dados em registros de comunicação ajuda a rastrear as interações de atendimento ao cliente para melhorar a experiência geral.
- Verificação de identidade: a automação da extração de dados dos documentos de comprovação de identidade ajuda a prevenir fraudes.
Contabilidade e finanças
- Processamento de faturas: A extração de dados desempenha um papel fundamental na automatização do processamento de faturas, extraindo com precisão detalhes relevantes das faturas.
- Conformidade fiscal: a extração de dados de formulários fiscais auxilia no cálculo correto das obrigações e divulgações fiscais.
- Relatórios financeiros: a automação da extração de dados de demonstrações financeiras ajuda a estabelecer um cenário preciso da saúde financeira de uma organização, oferecendo suporte a uma melhor tomada de decisões e transparência.
- Processamento de pedidos de compra: a extração automatizada de dados de ordens de compra permite a criação de registros confiáveis de compras, acelerando o processamento de pagamentos e dando suporte ao gerenciamento de orçamento.
Evolução da tecnologia de extração de dados.
Extração de dados melhor e mais rápida
Coletar, inserir e gerenciar dados comerciais exigia um esforço manual significativo para as organizações, basta pensar no trabalho de inserção de dados. Isso inspirou muitas das primeiras ferramentas de automação para extração de dados, como OCR, para otimizar e acelerar os processos de extração de dados. A extração das informações corretas e a estruturação dos dados em um formato utilizável foram aprimoradas pela introdução e refinamento de ferramentas, como SQL e processos ETL (Extract, Transform, Load; extrair, transformar, carregar), que permitiram a automação da extração de dados. No entanto, a extração de dados permaneceu amplamente baseada em regras e dependente de dados estruturados.
Quebra da barreira na estrutura com o ML
Com a introdução da RPA (robotic process automation, automação robótica de processos), a integração da IA e da ML (machine learning, aprendizado de máquina) representou um grande avanço na tecnologia de extração de dados. Extrair dados com mais precisão de fontes mais diversas e complexas foi possível graças aos algoritmos de ML que aprendem com dados históricos para melhorar a precisão e a eficiência ao longo do tempo. Modelos de ML, treinados para reconhecer e extrair pontos de dados específicos de fontes semiestruturadas, como e-mails ou faturas, possibilitaram uma grande redução na necessidade de intervenção manual na extração de dados, permitiram a mineração de dados e aumentaram de forma significativa a velocidade do processamento de dados.
Compreensão da linguagem natural
A aplicação da tecnologia de PLN transformou ainda mais o escopo e as capacidades das ferramentas de extração de dados. A capacidade de interpretar a linguagem humana com tecnologias de PLN significava que os processos de extração de dados podiam abranger dados de texto não estruturados, incluindo consultas de clientes e documentos comerciais, para coletar informações valiosas. Os algoritmos de PLN vão ainda mais longe, permitindo a compreensão do contexto, do sentimento e da intenção de dados de texto não estruturados em escala.
Potencial infinito com IA + automação
A combinação de IA, aprendizado de máquina, PLN e IA generativa com sistemas de automação cognitiva possibilita executar tarefas complexas de extração de dados com intervenção humana mínima. O IDP (Intelligent document processing, Processamento inteligente de documentos) e os sistemas avançados de automação baseados em IA são capazes de entender o contexto, aprender com novos dados e se adaptar às mudanças, possibilitando a automação de praticamente qualquer tarefa de extração de dados, incluindo fontes de dados não estruturadas, como áudio, vídeo e imagens. A extração de dados com tecnologia de IA permite que as organizações coletem e capitalizem os insights e o valor em repositórios de dados em constante crescimento para obter insights mais detalhados e impulsionar a inovação na economia orientada por dados.
Introdução à automação de extração de dados.
Identificar fontes de dados
Como os dados que você extrai dependem da sua fonte, identificá-la é um ponto de partida óbvio para configurar qualquer processo de extração de dados. Os dados de origem para extração podem incluir bancos de dados, sites, registros ou até mesmo documentos físicos.
Projetar o fluxo de trabalho de extração de dados
Examine cada estágio do processo de extração para mapear o fluxo de trabalho e definir regras para manuseio e processamento de dados. Comece definindo a conexão com suas fontes de dados e, em seguida, extraia os dados, transforme-os, valide-os e, por fim, carregue-os em seu destino.
Desenvolver e testar
Dependendo da fonte dos seus dados, você precisará utilizar diferentes ferramentas e técnicas de extração de dados, como raspagem de dados, consultas a bancos de dados, chamadas de API, OCR, análise de arquivos e PLN. Planeje testes abrangentes em um sandbox ou outro ambiente controlado e documente todo o processo de extração para dar suporte a qualquer possível solução de problemas.
Implantar e agendar
Programe a extração que será executada em intervalos específicos ou com base em determinados gatilhos ou condições para garantir produtividade máxima e interrupção mínima.
Monitorar e manter
Monitore o processo de extração para garantir a qualidade e a precisão contínuas dos dados. A revisão e a manutenção regulares podem ajudar a evitar falhas inesperadas ou problemas de desempenho devido a flutuações no volume de dados ou alterações no formato de origem. Por último, mas não menos importante, certifique-se de estabelecer protocolos de segurança de dados e revisões de conformidade.
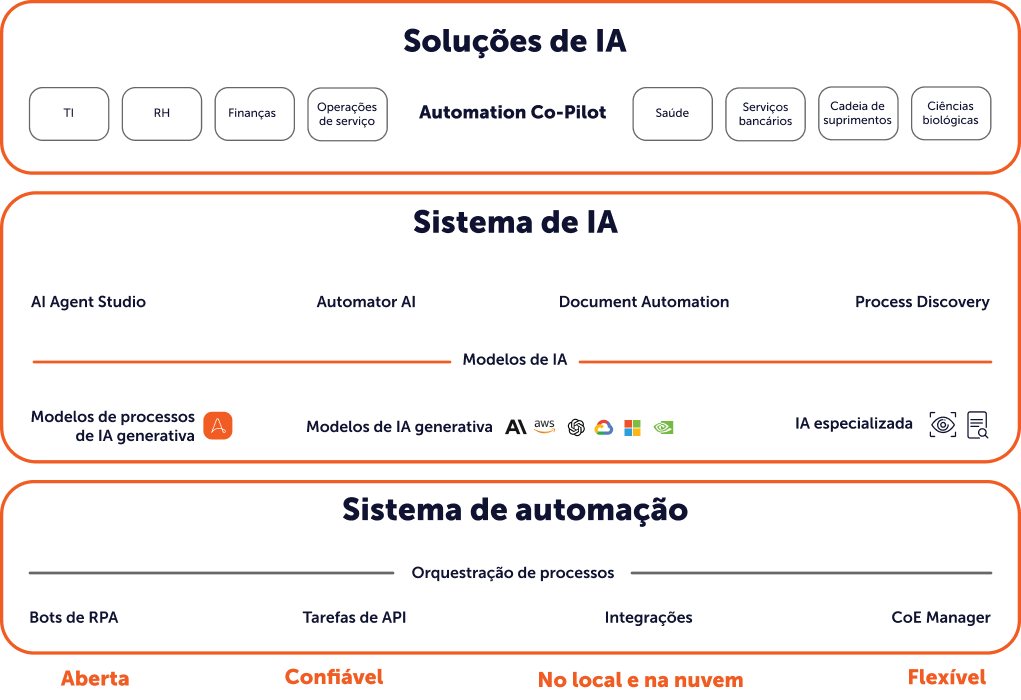
Extraia o máximo de valor dos seus dados com uma solução completa de Automação Inteligente.
Obtenha os recursos mais avançados de extração de dados com a Document Automation integrada à AI + Automation Enterprise System da Automation Anywhere. Identifique, colete e injete dados facilmente em qualquer processo ou fluxo de trabalho.