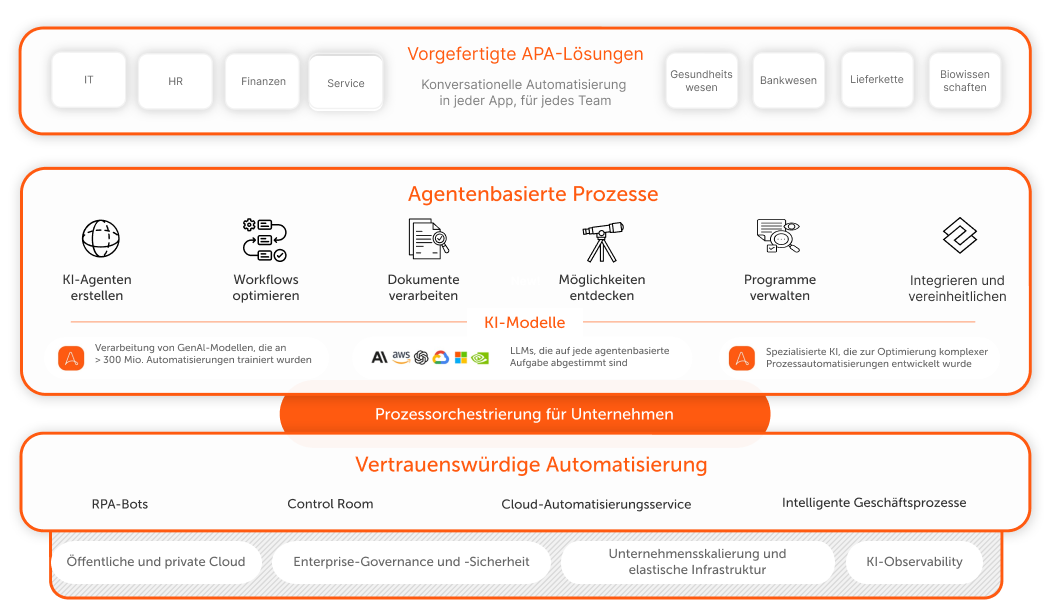
Was ist Datenextraktion?
Datenextraktion ist der Prozess des Sammelns spezifischer Daten aus Informationsquellen zur weiteren Verfeinerung und Nutzung in Geschäftsprozessen und Analysen.
Datenextraktion gilt für alle Arten von Daten aus sowohl strukturierten als auch unstrukturierten Datenquellen. Strukturierte Datenquellen wie Datenbanken und Tabellen sind organisiert und leicht zugänglich, während unstrukturierte Datenquellen wie Websites, APIs, Protokolldateien, Bilder und Textdateien fortgeschrittenere Extraktionsmethoden erfordern.
Vorteile der Datenextraktion
Verbesserte Entscheidungsfindung:
Datenextraktion kann aktuelle Informationen bereitstellen, um datengestützte Entscheidungen zu treffen, was die Geschäftsstrategie und -ergebnisse verbessert.
Bessere Datenqualität:
Automatisierte Datenextraktion minimiert Fehler bei der Datenmigration und -formatierung – für genaue und zuverlässige Daten.
Effizienzsteigerung:
Automatisierte Datenextraktion funktioniert nonstop und mit hoher Geschwindigkeit, spart Zeit und ermöglicht es den Mitarbeitenden, sich auf strategische, wertschöpfende Aktivitäten zu konzentrieren.
Schaffen neuer Werte:
Die Datenextraktion kann wertvolle Erkenntnisse aus ansonsten unbrauchbaren Dateien und Datensätzen aufdecken und latente Daten in wertvolle Ressourcen wie gezielte Leads und Betriebskosten verwandeln.
KI und maschinelles Lernen vorantreiben:
Die Datenextraktion kann wertvolle Insights für das Training von KI-Modellen liefern, indem alle Arten von Daten in organisierte und zentralisierte Informationsspeicher destilliert werden.
Tiefgehende Business Intelligence:
Unterstützt Initiativen zur Business Intelligence, die Unternehmen dabei helfen, Erkenntnisse aus Daten zu gewinnen, um Innovation und Wettbewerbsvorteile zu fördern.
Kosteneinsparungen:
Reduziert oder beseitigt manuelle Arbeiten im Datenmanagement, wodurch erhebliche Ressourcen und Kosten eingespart werden.
Datenverarbeitung im großen Maßstab:
Datenextraktionssoftware kann hohe Datenmengen aus mehreren Quellen verarbeiten und gleichzeitig steigende Datenmengen, einschließlich unerwarteter Änderungen im Volumen, reibungslos bewältigen.
Datenextraktion und ETL
Der „Extract, Transform, Load“-Prozess (ETL) ist eine dreiphasige Strategie, um Informationen zu sammeln, ihre Benutzerfreundlichkeit zu verbessern und sie in ein Datenökosystem zu integrieren.
Beginnend mit der Datenextraktion umfasst diese erste Phase das Anzapfen von Informationsquellen, um wesentliche Daten zu sammeln. Ähnlich wie die Qualität von Eingaben ein Endprodukt beeinflusst, legt die Gewährleistung, dass umfassende und zuverlässige Daten extrahiert werden, den Grundstein für den Erfolg des gesamten ETL-Workflows. In der „Transform“-Phase werden die extrahierten Rohdaten verfeinert, um den Geschäftszielen zu entsprechen. Datentransformation bzw. -umwandlung schafft Mehrwert, indem sie Daten an ihre beabsichtigte Verwendung anpasst und dabei überflüssige Komponenten entfernt. In der „Load“-Phase werden die Daten an ihren Bestimmungsort geliefert, in der Regel eine Datenbank, wo sie für die Nutzung in Geschäftsprozessen, Planung und Analyse bereitstehen.
Jeder Teil des ETL-Prozesses ist unverzichtbar, aber die Datenextraktion stellt den ersten grundlegenden Schritt dar, der eine effektive Datentransformation und -integration im weiteren Verlauf ermöglicht.
Datenquellen:
Bevor ein Extract, Transform, Load (ETL) Prozess initiiert wird, müssen die Datenquellen identifiziert werden. ETL-Tools können Rohdaten aus verschiedenen Quellen extrahieren, einschließlich strukturierter Datenbanken und CRM-Systemen, sowie aus unstrukturierten Quellen wie E-Mails und Websites.
Datenextraktion:
Dies ist der erste Schritt des ETL-Prozesses. ETL-Tools extrahieren Rohdaten aus den identifizierten Quellen und speichern sie vorübergehend in einem Staging-Bereich. Abhängig von der Datenquelle und dem Zweck könnte der Prozess eine vollständige Extraktion oder eine inkrementelle Extraktion verwenden. Ebenso hängt die Häufigkeit der Extraktion, ob in Echtzeit oder in festgelegten Intervallen, von den spezifischen Bedürfnissen des Geschäftsprozesses oder Ziels ab.
Datentransformation:
Sobald die Daten extrahiert wurden, beginnt die Transformationsphase, um die Rohdaten zu bereinigen, zu organisieren und zu konsolidieren. Daten können verschiedenen Transformationen unterzogen werden, einschließlich Datenbereinigung, Entfernung von Duplikaten und Umformatierung.
Daten laden:
Der letzte Schritt im ETL-Prozess besteht darin, die transformierten Daten zu laden. Diese Daten, jetzt verfeinert und fehlerfrei, werden in das Ziel-Data Warehouse übertragen und gespeichert. Je nach Datenvolumen und geschäftlichen Anforderungen kann der Ladevorgang entweder auf einmal oder schrittweise erfolgen. Sobald die Daten geladen sind, sind sie bereit für den Abruf und die Analyse.
Datenextraktionsmethoden und -tools
Automatisierung kann nur so weit gehen, wie die verfügbaren Daten es zulassen. Daher ist eine effektive Datenextraktion und -organisation der Schlüssel zur Automatisierung der meisten Geschäftsprozesse. Verschiedene Datenextraktionsmethoden und -tools werden verwendet, um Informationen aus Datenquellen in unterschiedlichen Formaten zu sammeln. Insbesondere sind KI-gestützte Technologien zur Intelligenten Automatisierung notwendig, um Daten aus unstrukturierten Quellen wie E-Mails und Geschäftsdokumenten zu gewinnen.
Strukturierte Datenextraktion
Strukturierte Daten, gekennzeichnet durch ihr vororganisiertes Format und die einfache Zugänglichkeit, befinden sich typischerweise in Datenbanken, Tabellen und Customer Relationship Management-Systemen (CRM). Das Extrahieren strukturierter Daten ist in der Regel unkompliziert und verwendet eine Reihe von Techniken wie SQL-Abfragen, API-Aufrufe und spezifische Datenbankverwaltungstools.
Dennoch bringen strukturierte Daten gewisse Herausforderungen bei der Datenextraktion mit sich. Hohe Datenvolumen können Extraktionsprozesse verlangsamen, während Daten, die in getrennten Systemen isoliert sind, zu komplexen Integrationsprozessen führen können. Das Extrahieren sensibler Daten wie etwa Kundeninformationen bringt zudem Datenschutz-, Compliance- und Sicherheitsüberlegungen mit sich.
Häufige Methoden zur Extraktion strukturierter Daten:
- SQL (Structured Query Language = Strukturierte Abfragesprache) ist die Standardsprache für die Interaktion mit relationalen Datenbanken. SQL-Abfragen sind leistungsstarke Tools zum Extrahieren, Manipulieren und Verwalten von Daten.
- APIs (Application Programming Interfaces = Anwendungsprogrammierschnittstellen) ermöglichen es Systemen, programmgesteuert zu kommunizieren und Daten auszutauschen. Sie sind entscheidend für die Extraktion von Daten aus cloudbasierten Anwendungen und Diensten.
- Datenbankverwaltungstools sind spezialisiert auf die Verwaltung und Extraktion von Daten aus strukturierten Quellen, die typischerweise benutzerfreundliche Schnittstellen mit zusätzlichen, fortgeschritteneren Funktionen bieten. Spezialisierte Datenextraktionstools umfassen:
- ETL-Tools zur Automatisierung des Prozesses der Datenextraktion, -transformation und -ladung in Data Warehouses
- Datenintegrationsplattformen, die die Integration von Daten aus mehreren strukturierten Quellen in ein einzelnes System erleichtern
- CRM-Datenextraktoren ziehen Daten aus CRM-Systemen für Analysen und Berichterstattung
Extraktion halbstrukturierter Daten
Im Gegensatz zu strukturierten Daten halten sich halbstrukturierte Daten nicht an ein festes Schema, enthält jedoch Tags und Marker, die eine organisatorische Hierarchie bieten. Häufige Quellen für halbstrukturierte Daten sind XML-Dateien, JSON-Dateien und Webdaten.
Die Extraktion von halbstrukturierten Daten stellt aufgrund der Variabilität und Vielfalt der Daten eine besondere Herausforderung dar, die die Standardisierung und Normalisierung komplexer macht. Ähnlich wie unstrukturierte Daten kann das schiere Volumen und die Geschwindigkeit, mit der halbstrukturierte Daten erzeugt werden, die fortlaufende Datenextraktion herausfordernder machen. Zusätzlich können einige Datenformate, wie XML- und JSON-Dateien, verschachtelte Strukturen aufweisen, die die Anwendung spezifischer Parsing-Techniken erfordern.
Häufige Methoden zur Extraktion halbstrukturierter Daten:
- eXtensible Markup Language-Dateien (XML) werden häufig für die Darstellung und den Austausch von Daten verwendet. XML-Parser sind unerlässlich für das Lesen und Extrahieren von Daten aus XML-Dokumenten.
- JavaScript Object Notation (JSON) ist ein leichtes Datenformat für den Austausch, das aufgrund seiner Einfachheit und Lesbarkeit beliebt ist. JSON-Datenextraktoren analysieren und verarbeiten JSON-Dateien.
- Web Scraping beinhaltet das Extrahieren von Daten von Websites, die dazu neigen, Informationen in halbstrukturierten Formaten darzustellen. Web Scraping-Tools automatisieren den Prozess des Webdatenabrufs.
Extraktion unstrukturierter Daten
Unstrukturierte Daten sind das ungezähmte Kind der Geschäftsinformationen: Unvorhersehbar, aber mit immensem Potenzial für die Wertschöpfung. Die Realität ist, dass der Großteil der Daten in unstrukturiertem Format vorliegt, verteilt über E-Mails, Dokumente und Chats sowie Audio-, Video- und Bilddateien. Die Nutzung unstrukturierter Datenquellen zur Gewinnung von Erkenntnissen erfordert fortschrittliche Methoden und Technologien wie NLP, OCR und KI-gestützte Textanalysetools, um die Herausforderungen zu meistern, die mit der Verarbeitung komplexer Daten ohne vordefiniertes Schema verbunden sind.
Herausforderungen, die speziell mit der Extraktion unstrukturierter Daten einhergehen, umfassen das Volumen und die Vielfalt der Daten sowie deren Kontext – Sarkasmus in Chat-Gesprächen oder die Verwendung von Terminologie außerhalb des Kontextes – was eine beispiellose Komplexität schafft. Die Gewährleistung von Genauigkeit und Datenintegrität ist ebenfalls eine Herausforderung aufgrund von sogenanntem „Noise“ (Störungen oder irrelevante Informationen) und der Variabilität, die unstrukturierte Datenquellen mit sich bringen.
Häufige Methoden zur Extraktion unstrukturierter Daten:
- OCR (Optical Character Recognition = Optische Zeichenerkennung) wandelt verschiedene Arten von Dokumenten, wie gescannte Papierdokumente, PDFs oder digitale Bilder, in bearbeitbare und durchsuchbare Daten um.
- NLP (Natural Language Processing = Verarbeitung natürlicher Sprache) ist eine Kerntechnologie zum Extrahieren und Verstehen unstrukturierter Texte. NLP umfasst mehrere Techniken:
- Tokenisierung: Unterteilung des Textes in einzelne Wörter oder Phrasen
- NER (Named Entity Recognition = Eigennamenerkennung): Identifizierung und Klassifizierung von Entitäten wie Namen, Daten und Orten
- Sentimentanalyse: Analyse des Sentiments hinter dem Text, um die öffentliche Meinung oder Kundenfeedback einzuschätzen
- Textzusammenfassung: Extrahieren von wichtigen Punkten aus großen Dokumenten
- Andere KI-gestützte Textanalysen-Tools kombinieren maschinelles Lernen und Deep Learning-Techniken, um Erkenntnisse aus unstrukturierten Daten zu gewinnen. Die Techniken umfassen die Themenmodellierung zur Identifizierung der Hauptthemen in einem großen Textkorpus, das Clustering zur Gruppierung ähnlicher Dokumente oder Textausschnitte und prädiktive Analytik zur Vorhersage zukünftiger Trends anhand historischer Daten.
Anwendungsfälle für die Automatisierung der Datenextraktion
Bankwesen und Finanzdienstleistungen
- Kreditbearbeitung: Die Anwendung automatisierter Datenextraktion auf Kreditanträge ermöglicht die Beurteilung der Bonität und Rückzahlungsfähigkeit von Kreditnehmern in Echtzeit.
- Onboarding von Kunden: Die automatische Datenextraktion aus Kontoeröffnungsformularen beschleunigt die Kontoeinrichtung.
- Finanzberichterstattung: Die Automatisierung der Datenextraktion unterstützt eine genaue und zeitnahe Verfolgung von Ausgaben und Budgetierung.
- Know Your Customer (KYC): Die Automatisierung der Extraktion von Kundeninformationen aus Kontoeröffnungsformularen hilft, die Überprüfung der Identitäten der Kunden zu beschleunigen.
Gesundheitsbranche
- Verwaltung von Patientenakten: Die Automatisierung der Datenextraktion beschleunigt die Organisation und Verwaltung medizinischer Unterlagen und unterstützt die Genauigkeit und Zugänglichkeit von Patienteninformationen.
- Verwaltungseffizienz: Die Automatisierung der Datenauswertung reduziert die administrative Arbeitsbelastung, erhöht die Genauigkeit und Geschwindigkeit und entlastet das Personal, damit es sich auf die Patientenversorgung konzentrieren kann.
- Compliance-Angelegenheiten: Die Datenextraktion automatisiert den Prozess der Erfassung erforderlicher Daten aus Compliance-relevanten Dokumenten.
- Elektronische Gesundheitsakte (eGA): Automatisierte Datenerfassung ermöglicht die Einführung elektronischer Gesundheitsakten und erleichtert die effiziente Speicherung, den Abruf und die Weitergabe von Patientendaten.
Versicherungen
- Verwaltung von Richtliniendokumenten: Die Automatisierung der Datenextraktion aus Policendokumenten hilft, genaue Versicherungsbedingungen und -konditionen sicherzustellen.
- Schadenbearbeitung: Automatisierte Datenextraktion aus Anspruchsformularen ermöglicht das Erfassen von Vorfalldetails so schnell wie möglich.
- Kundenservice: Die Automatisierung der Datenextraktion aus Kommunikationsaufzeichnungen hilft dabei, Kundenservice-Interaktionen zu verfolgen, um das Gesamterlebnis der Kunden zu verbessern.
- Identitätsüberprüfung: Die Automatisierung der Datenextraktion aus Identitätsnachweisdokumenten hilft, Betrug zu verhindern.
Buchhaltung und Finanzen
- Rechnungsbearbeitung: Die Datenextraktion spielt eine Schlüsselrolle bei der Automatisierung der Rechnungsverarbeitung, indem sie relevante Details aus Rechnungen genau extrahiert.
- Steuer-Compliance: Das Extrahieren von Daten aus Steuerformularen unterstützt die korrekte Berechnung von Steuerverpflichtungen und -offenlegungen.
- Finanzberichterstattung: Die Automatisierung der Datenextraktion aus Finanzberichten hilft, ein genaues Bild der finanziellen Gesundheit einer Organisation zu erstellen, was bessere Entscheidungen und Transparenz unterstützt.
- Bestellabwicklung: Automatisierte Datenextraktion aus Bestellungen ermöglicht die Erstellung zuverlässiger Einkaufsunterlagen, beschleunigt die Zahlungsabwicklung und unterstützt das Budgetmanagement.
Entwicklung der Datenextraktionstechnologie
Bessere, schnellere Datenextraktion
Die Erhebung, Eingabe und Verwaltung von Geschäftsdaten stellte einen erheblichen manuellen Aufwand für Organisationen dar – denken Sie nur an die Arbeit der Dateneingabe – und inspirierte viele der ersten Automatisierungstools wie OCR zur Datenextraktion, um die Datenextraktionsprozesse zu optimieren und zu beschleunigen. Die Extraktion der richtigen Informationen und die Strukturierung der Daten in ein verwendbares Format wurden durch die Einführung und Verfeinerung von Tools wie SQL und „Extract, Transform, Load“-Prozessen (ETL) verbessert, die die Automatisierung der Datenextraktion ermöglichten. Allerdings blieb die Datenextraktion weitgehend regelbasiert und abhängig von strukturierten Daten.
Die Strukturbarriere mit ML durchbrechen
Zusammen mit der Einführung der Robotergesteuerten Prozessautomatisierung (RPA) stellte die Integration von KI und maschinellem Lernen (ML) einen bedeutenden Durchbruch in der Datenextraktionstechnologie dar. Eine genauere Datenextraktion aus vielfältigeren und komplexeren Quellen wurde durch ML-Algorithmen ermöglicht, die aus historischen Daten lernen, um die Genauigkeit und Effizienz im Laufe der Zeit zu verbessern. ML-Modelle, die darauf trainiert sind, spezifische Datenpunkte aus halbstrukturierten Quellen wie E-Mails oder Rechnungen zu erkennen und zu extrahieren, führten zu einer erheblichen Reduzierung des Bedarfs an manuellem Eingreifen bei der Datenextraktion, ermöglichten Data Mining und erhöhten die Geschwindigkeit der Datenverarbeitung massiv.
Verständnis natürlicher Sprache
Die Anwendung von Technologien zur Verarbeitung natürlicher Sprache (NLP) hat den Umfang und die Fähigkeiten von Datenextraktionstools weiter transformiert. Die Fähigkeit, menschliche Sprache mit NLP-Technologien zu interpretieren, bedeutete, dass Datenextraktionsprozesse unstrukturierte Textdaten, einschließlich Kundenanfragen und Geschäftsdokumente, umfassen konnten, um wertvolle Informationen zu gewinnen. NLP-Algorithmen gehen noch weiter und ermöglichen das Verständnis von Kontext, Sentiment (Stimmung) und Absicht unstrukturierter Textdaten in großem Maßstab.
Unendliches Potenzial mit KI und Automatisierung
Durch die Kombination von KI, maschinellem Lernen, NLP und generativer KI mit kognitiven Automatisierungssystemen eröffnet sich die Möglichkeit, komplexe Datenextraktionsaufgaben mit minimalem menschlichen Eingreifen durchzuführen. IDP (Intelligent document processing = Intelligente Dokumentenverarbeitung) und fortschrittliche KI-gesteuerte Automatisierungssysteme können Kontexte verstehen, aus neuen Daten lernen und sich an Veränderungen anpassen, wodurch nahezu jede Datenextraktionsaufgabe für die Automatisierung geeignet ist, einschließlich unstrukturierter Datenquellen wie Audio, Video und Bilder. KI-gestützte Datenextraktion ermöglicht es Organisationen, die Erkenntnisse und den Wert aus ständig wachsenden Datenbeständen zu sammeln und zu nutzen, um tiefere Insights zu gewinnen und Innovationen in der datengestützten Wirtschaft voranzutreiben.
Erste Schritte mit der Automatisierung der Datenextraktion
Datenquellen identifizieren
Da die Daten, die Sie extrahieren, von ihrer Quelle abhängen, ist die Identifizierung Ihrer Datenquelle ein offensichtlicher Ausgangspunkt für die Einrichtung eines Datenextraktionsprozesses. Quelldaten für die Extraktion können Datenbanken, Websites, Protokolle oder sogar physische Dokumente umfassen.
Datenextraktions-Workflow erstellen
Untersuchen Sie jede Phase des Extraktionsprozesses, um den Workflow zu skizzieren und Regeln für die Datenhandhabung und -verarbeitung festzulegen. Beginnen Sie mit der Einrichtung der Verbindung zu Ihren Datenquellen, extrahieren Sie dann die Daten, transformieren und validieren Sie sie und laden Sie schließlich die Daten an ihrem Bestimmungsort.
Entwicklung und Test
Abhängig von der Quelle Ihrer Daten müssen Sie verschiedene Datenextraktionstools und Techniken einsetzen, z. B. Web-Scraping, Datenbankabfragen, API-Aufrufe, OCR, Dateianalyse und NLP. Planen Sie umfassende Tests in einer Sandbox oder einer anderen kontrollierten Umgebung und dokumentieren Sie den gesamten Extraktionsprozess vollständig, um eine mögliche Fehlerbehebung zu unterstützen.
Bereitstellen und planen
Planen Sie die Extraktion so, dass sie in bestimmten Intervallen oder basierend auf bestimmten Auslösern oder Bedingungen ausgeführt wird, um maximale Produktivität und minimale Störungen zu gewährleisten.
Überwachen und warten
Überwachen Sie den Extraktionsprozess, um die kontinuierliche Datenqualität und Genauigkeit sicherzustellen. Regelmäßige Überprüfung und Wartung können helfen, unerwartete Ausfälle oder Leistungsprobleme aufgrund von Schwankungen im Datenvolumen oder Änderungen im Quellformat zu vermeiden. Zu guter Letzt sollten Sie sicherstellen, dass Daten-Sicherheitsprotokolle und Compliance-Überprüfungen eingerichtet werden.
Volle Wertschöpfung Ihrer Daten mit einer umfassenden Intelligenten Automatisierungslösung
Erhalten Sie die fortschrittlichsten Datenextraktionsfunktionen mit Document Automation, integriert in das AI + Automation Enterprise System von Automation Anywhere. So können Sie in jedem Prozess oder Workflow nahtlos Daten identifizieren, erheben und einfügen.